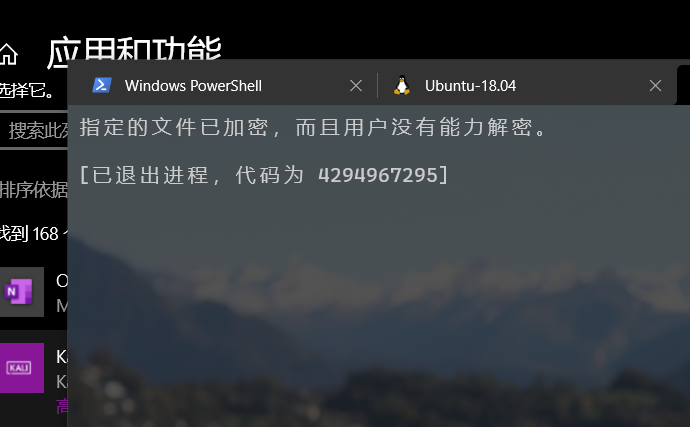
Windows PowerShell 版权所有 (C) Microsoft Corporation。保留所有权利。
尝试新的跨平台 PowerShell https://aka.ms/pscore6
PS C:\Users\DELL> python --version Python 3.8.6 PS C:\Users\DELL> nvcc -V nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2019 NVIDIA Corporation Built on Wed_Oct_23_19:32:27_Pacific_Daylight_Time_2019 Cuda compilation tools, release 10.2, V10.2.89 PS C:\Users\DELL> python Python 3.8.6 (tags/v3.8.6:db45529, Sep 23 2020, 15:52:53) [MSC v.1927 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license"for more information. >>> import torch >>> print(torch.__version__) 1.10.0+cu102 >>> import tensorflow as tf 2021-11-21 12:17:03.769777: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cudart64_101.dll >>> print(tf.__version__) 2.3.0 >>> print(torch.cuda.is_available()) True >>> tf.test.is_gpu_available() WARNING:tensorflow:From <stdin>:1: is_gpu_available (from tensorflow.python.framework.test_util) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.config.list_physical_devices('GPU')` instead. 2021-11-21 12:19:43.396815: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN)to use the following CPU instructions in performance-critical operations: AVX2 To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags. 2021-11-21 12:19:43.406420: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x1da756cae50 initialized for platform Host (this does not guarantee that XLA will be used). Devices: 2021-11-21 12:19:43.406558: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version 2021-11-21 12:19:43.406737: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library nvcuda.dll 2021-11-21 12:19:43.406971: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1716] Found device 0 with properties: pciBusID: 0000:01:00.0 name: NVIDIA GeForce GTX 1650 computeCapability: 7.5 coreClock: 1.56GHz coreCount: 16 deviceMemorySize: 4.00GiB deviceMemoryBandwidth: 119.24GiB/s 2021-11-21 12:19:43.407083: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cudart64_101.dll 2021-11-21 12:19:43.407208: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cublas64_10.dll 2021-11-21 12:19:43.407387: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cufft64_10.dll 2021-11-21 12:19:43.407520: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library curand64_10.dll 2021-11-21 12:19:43.407593: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cusolver64_10.dll 2021-11-21 12:19:43.407740: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cusparse64_10.dll 2021-11-21 12:19:43.407894: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cudnn64_7.dll 2021-11-21 12:19:43.408023: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1858] Adding visible gpu devices: 0 2021-11-21 12:19:45.176360: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1257] Device interconnect StreamExecutor with strength 1 edge matrix: 2021-11-21 12:19:45.176465: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1263] 0 2021-11-21 12:19:45.176528: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1276] 0: N 2021-11-21 12:19:45.176750: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1402] Created TensorFlow device (/device:GPU:0 with 2905 MB memory) -> physical GPU (device: 0, name: NVIDIA GeForce GTX 1650, pci bus id: 0000:01:00.0, compute capability: 7.5) 2021-11-21 12:19:45.179856: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x1da3ed8bce0 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices: 2021-11-21 12:19:45.179952: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): NVIDIA GeForce GTX 1650, Compute Capability 7.5 True >>>
murphy-ubuntu@Murphy-DELL:/mnt/c/Users/DELL$ python Python 3.6.9 (default, Jan 26 2021, 15:33:00) [GCC 8.4.0] on linux Type "help", "copyright", "credits" or "license"for more information. >>> import tensorflow 2021-11-21 14:34:29.474127: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0 >>> import torch >>> print(torch.cuda.is_available()) True >>>
murphy-ubuntu@Murphy-DELL:/mnt/c/Users/DELL$ python Python 3.6.9 (default, Jan 26 2021, 15:33:00) [GCC 8.4.0] on linux Type "help", "copyright", "credits" or "license"for more information. >>> import tensorflow as tf >>> tf.test.is_gpu_available() WARNING:tensorflow:From <stdin>:1: is_gpu_available (from tensorflow.python.framework.test_util) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.config.list_physical_devices('GPU')` instead. 2021-11-21 14:36:24.495813: I tensorflow/compiler/jit/xla_gpu_device.cc:99] Not creating XLA devices, tf_xla_enable_xla_devices not set 2021-11-21 14:36:24.496873: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcuda.so.1 2021-11-21 14:36:24.498697: E tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:927] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node Your kernel may have been built without NUMA support. 2021-11-21 14:36:24.498759: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1720] Found device 0 with properties: pciBusID: 0000:01:00.0 name: NVIDIA GeForce GTX 1650 computeCapability: 7.5 coreClock: 1.56GHz coreCount: 16 deviceMemorySize: 4.00GiB deviceMemoryBandwidth: 119.24GiB/s 2021-11-21 14:36:24.498799: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0 2021-11-21 14:36:24.516945: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublas.so.11 2021-11-21 14:36:24.517034: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublasLt.so.11 2021-11-21 14:36:24.532660: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcufft.so.10 2021-11-21 14:36:24.538639: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcurand.so.10 2021-11-21 14:36:24.557670: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusolver.so.10 2021-11-21 14:36:24.562764: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusparse.so.11 2021-11-21 14:36:24.564244: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudnn.so.8 2021-11-21 14:36:24.564836: E tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:927] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node Your kernel may have been built without NUMA support. 2021-11-21 14:36:24.565348: E tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:927] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node Your kernel may have been built without NUMA support. 2021-11-21 14:36:24.566200: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1862] Adding visible gpu devices: 0 2021-11-21 14:36:24.566892: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0 2021-11-21 14:36:26.926735: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1261] Device interconnect StreamExecutor with strength 1 edge matrix: 2021-11-21 14:36:26.926810: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1267] 0 2021-11-21 14:36:26.926840: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1280] 0: N 2021-11-21 14:36:26.928867: E tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:927] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node Your kernel may have been built without NUMA support. 2021-11-21 14:36:26.928923: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1489] Could not identify NUMA node of platform GPU id 0, defaulting to 0. Your kernel may not have been built with NUMA support. 2021-11-21 14:36:26.929470: E tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:927] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node Your kernel may have been built without NUMA support. 2021-11-21 14:36:26.929971: E tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:927] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node Your kernel may have been built without NUMA support. 2021-11-21 14:36:26.930033: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1406] Created TensorFlow device (/device:GPU:0 with 2875 MB memory) -> physical GPU (device: 0, name: NVIDIA GeForce GTX 1650, pci bus id: 0000:01:00.0, compute capability: 7.5) True
murphy-ubuntu@Murphy-DELL:/mnt/c/Users/DELL$ nvcc -V nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2020 NVIDIA Corporation Built on Wed_Jul_22_19:09:09_PDT_2020 Cuda compilation tools, release 11.0, V11.0.221 Build cuda_11.0_bu.TC445_37.28845127_0 murphy-ubuntu@Murphy-DELL:/mnt/c/Users/DELL$ python Python 3.6.9 (default, Jan 26 2021, 15:33:00) [GCC 8.4.0] on linux Type "help", "copyright", "credits" or "license"for more information. >>> import torch >>> import tensorflow as tf 2021-11-21 14:38:07.986815: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0 >>> print(torch.__version__) 1.7.1+cu110 >>> print(tf.__version__) 2.4.0 >>> print(torch.cuda.test_gpu_abailable()) Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: module 'torch.cuda' has no attribute 'test_gpu_abailable' >>> print(torch.cuda.is_available()) True >>> tf.test.is_gpu_available() WARNING:tensorflow:From <stdin>:1: is_gpu_available (from tensorflow.python.framework.test_util) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.config.list_physical_devices('GPU')` instead. 2021-11-21 14:39:05.764557: I tensorflow/compiler/jit/xla_gpu_device.cc:99] Not creating XLA devices, tf_xla_enable_xla_devices not set 2021-11-21 14:39:05.764673: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcuda.so.1 2021-11-21 14:39:05.765235: E tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:927] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node Your kernel may have been built without NUMA support. 2021-11-21 14:39:05.765340: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1720] Found device 0 with properties: pciBusID: 0000:01:00.0 name: NVIDIA GeForce GTX 1650 computeCapability: 7.5 coreClock: 1.56GHz coreCount: 16 deviceMemorySize: 4.00GiB deviceMemoryBandwidth: 119.24GiB/s 2021-11-21 14:39:05.765400: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0 2021-11-21 14:39:05.767384: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublas.so.11 2021-11-21 14:39:05.767443: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublasLt.so.11 2021-11-21 14:39:05.768263: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcufft.so.10 2021-11-21 14:39:05.768539: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcurand.so.10 2021-11-21 14:39:05.771097: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusolver.so.10 2021-11-21 14:39:05.771751: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusparse.so.11 2021-11-21 14:39:05.771888: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudnn.so.8 2021-11-21 14:39:05.772427: E tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:927] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node Your kernel may have been built without NUMA support. 2021-11-21 14:39:05.772838: E tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:927] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node Your kernel may have been built without NUMA support. 2021-11-21 14:39:05.772878: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1862] Adding visible gpu devices: 0 2021-11-21 14:39:05.772930: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0 2021-11-21 14:39:11.938306: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1261] Device interconnect StreamExecutor with strength 1 edge matrix: 2021-11-21 14:39:11.938386: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1267] 0 2021-11-21 14:39:11.938421: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1280] 0: N 2021-11-21 14:39:11.939059: E tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:927] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node Your kernel may have been built without NUMA support. 2021-11-21 14:39:11.939098: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1489] Could not identify NUMA node of platform GPU id 0, defaulting to 0. Your kernel may not have been built with NUMA support. 2021-11-21 14:39:11.939505: E tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:927] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node Your kernel may have been built without NUMA support. 2021-11-21 14:39:11.939939: E tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:927] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node Your kernel may have been built without NUMA support. 2021-11-21 14:39:11.940011: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1406] Created TensorFlow device (/device:GPU:0 with 1951 MB memory) -> physical GPU (device: 0, name: NVIDIA GeForce GTX 1650, pci bus id: 0000:01:00.0, compute capability: 7.5) True >>>
The results reported in our paper are originally based on PyTorch-Encoding but the environment settings are a little bit complicated. To ease use, we reimplement our work based on semseg.
import cv2 import numpy as np import os.path import copy
# 椒盐噪声 defSaltAndPepper(src,percetage): SP_NoiseImg=src.copy() SP_NoiseNum=int(percetage*src.shape[0]*src.shape[1]) for i inrange(SP_NoiseNum): randR=np.random.randint(0,src.shape[0]-1) randG=np.random.randint(0,src.shape[1]-1) randB=np.random.randint(0,3) if np.random.randint(0,1)==0: SP_NoiseImg[randR,randG,randB]=0 else: SP_NoiseImg[randR,randG,randB]=255 return SP_NoiseImg
# 高斯噪声 defaddGaussianNoise(image,percetage): G_Noiseimg = image.copy() w = image.shape[1] h = image.shape[0] G_NoiseNum=int(percetage*image.shape[0]*image.shape[1]) for i inrange(G_NoiseNum): temp_x = np.random.randint(0,h) temp_y = np.random.randint(0,w) G_Noiseimg[temp_x][temp_y][np.random.randint(3)] = np.random.randn(1)[0] return G_Noiseimg
# 昏暗 defdarker(image,percetage=0.9): image_copy = image.copy() w = image.shape[1] h = image.shape[0] #get darker for xi inrange(0,w): for xj inrange(0,h): image_copy[xj,xi,0] = int(image[xj,xi,0]*percetage) image_copy[xj,xi,1] = int(image[xj,xi,1]*percetage) image_copy[xj,xi,2] = int(image[xj,xi,2]*percetage) return image_copy
# 亮度 defbrighter(image, percetage=1.5): image_copy = image.copy() w = image.shape[1] h = image.shape[0] #get brighter for xi inrange(0,w): for xj inrange(0,h): image_copy[xj,xi,0] = np.clip(int(image[xj,xi,0]*percetage),a_max=255,a_min=0) image_copy[xj,xi,1] = np.clip(int(image[xj,xi,1]*percetage),a_max=255,a_min=0) image_copy[xj,xi,2] = np.clip(int(image[xj,xi,2]*percetage),a_max=255,a_min=0) return image_copy
# 旋转 defrotate(image, angle, center=None, scale=1.0): (h, w) = image.shape[:2] # If no rotation center is specified, the center of the image is set as the rotation center if center isNone: center = (w / 2, h / 2) m = cv2.getRotationMatrix2D(center, angle, scale) rotated = cv2.warpAffine(image, m, (w, h)) return rotated