ILSVRC论文
ILSVRC
ImageNet
一切的起源:CVPR 2009,*ImageNet: A large-scale hierarchical image database*
ImageNet is an image database organized according to the WordNet hierarchy (currently only the nouns), in which each node of the hierarchy is depicted by hundreds and thousands of images. The project has been instrumental in advancing computer vision and deep learning research. The data is available for free to researchers for non-commercial use.[2]
另外还有一篇2015年的论文,*ImageNet Large Scale Visual Recognition Challenge*
- 14,192,122 million images, 21841 thousand categories
ImageNet数据集的出现,直接证明了庞大的数据是可以推动计算机视觉的进步的!
ILSVRC
ILSVRC无论怎么来介绍,都不如ImageNet官方给出的介绍来得直接明了!
The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) evaluates algorithms for object detection and image classification at large scale.
One high level motivation is to allow researchers to compare progress in detection across a wider variety of objects – taking advantage of the quite expensive labeling effort.
Another motivation is to measure the progress of computer vision for large scale image indexing for retrieval and annotation.[1]
ILSVRC从2010年到2017年,总共举办了八届,但直到2012年AlexNet的横空出世,才使得ILSVRC得到了更多人的关注。在2017年之后,模型在ImageNet数据集上的错误率已经被“刷爆”了,再继续下去也已经没有什么意义了,ImageNet已经完成了它最初的使命了!
ILSVRC 2010
2010年只有分类任务
Winner: NEC-UIUC
Yuanqing Lin, Fengjun Lv, Shenghuo Zhu, Ming Yang, Timothee Cour, Kai Yu (NEC). LiangLiang Cao, Zhen Li, Min-Hsuan Tsai, Xi Zhou, Thomas Huang (UIUC). Tong Zhang (Rutgers).
[PDF] NB: This is unpublished work. Please contact the authors if you plan to make use of any of the ideas presented.
- Fast descriptor coding
- Large-scale SVM classification
Honorable mention: XRCE
Jorge Sanchez, Florent Perronnin, Thomas Mensink (XRCE)
[PDF] NB: This is unpublished work. Please contact the authors if you plan to make use of any of the ideas presented.
- Fisher Vector
ILSVRC 2011
Categorization&Localization
Classification Winners: XRCE
Florent Perronnin, Jorge Sanchez
[PDF] Compressed Fisher vectors for Large Scale Visual Recognition
Detection Winners: University of Amsterdam & University of Trento
Koen van de Sande, Jasper Uijlings
Arnold Smeulders, Theo Gevers, Nicu Sebe, Cees Snoek
[PDF] Segmentation as Selective Search for Object Recognition
ILSVRC 2012
review [ slides ]
Task 1: Classification: SuperVision [ slides ];OXFORD_VGG team [ slides ]
Task 2: Classification with localization: SuperVision
Task 3: Fine-grained classification: ISI [ slides ]
AlexNet (NeurIPS 2012)✅
📄paper: ImageNet Classification with Deep Convolutional Neural Networks (neurips.cc)
💻code:
Deep Convolutional Neural Network
No any unsupervised pre-training
- 在AlexNet之前,机器学习界还是更关心unsupervised learning
- AlexNet之后,都在做supervised learning
- BERT在自然语言处理任务的兴起后,大家又把注意力放到了unsupervised learning了
Computational power
next: video?
深度神经网络对一张图片进行训练后得到的那个向量,在语义空间内的表示特别好!这是深度学习的一大强项!
larger datasets, more powerful models, less overfitting
a model with large learning capacity
GPU
contributions: largest CNN; GPU; solve overfitting; depth!
two GTX 580 3GB GPUs(对于这篇文章来说,作者将模型划分到了两个GPU上,虽然工程上的工作量很大,但大家都不怎么care)
ImageNet中的图像大小都不一样,作者将其预处理为256×256
- AlexNet没用使用SIFT这种特征提取方法,而是直接对raw RGB图像进行处理,这种端到端(End to End)的工作对后续的工作有重大影响。
detail
- SGD; batch size:128; momentum: 0.9; weight decay: 0.0005
- initialized the weight: 0-means Gaussian distribution with standard deviation 0.01
- initialized the biases
- equal learning rate for all layers; initialized the learning rate 0.01
上层神经元学到的是“全局”特征,如形状;底层神经元学到的是“局部”特征,如纹理。
🚩Contribution 1: Architecture
ReLU
- Saturating nonlinearities: tanh or sigmoid
- Non-saturating nonlinearities: ReLU, $ f(x) = max(0, x)$
- Rectified Linear Units Improve Restricted Boltzmann Machines (toronto.edu)
Multi GPUs
- 太工程了!
Local Response Normalization
- 现在已经有更好的Normalization技术了
Overlapping Pooling
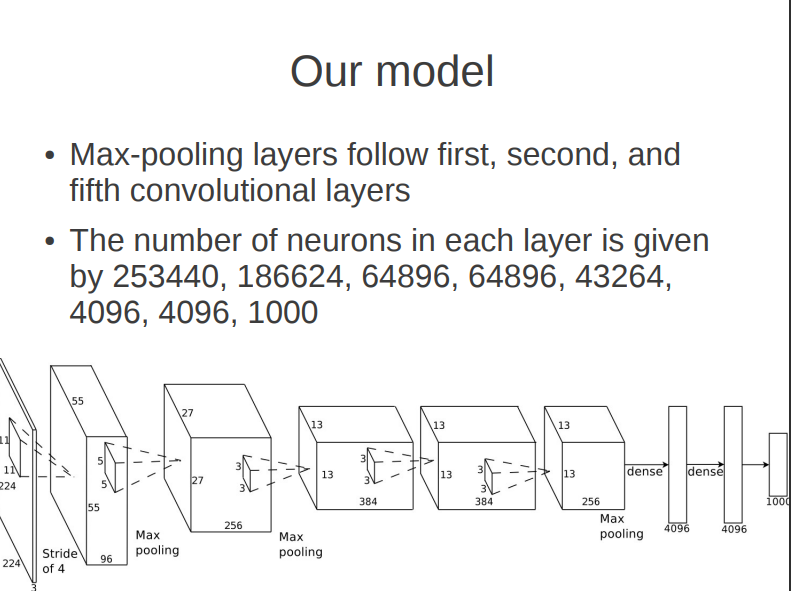
- 这么长的网络结构就是将一张图像的像素信息转化成了最终长为1000的向量。这个向量了丰富包含的语义信息(机器看得懂),是深度学习的一大优势所在!
- 所以说机器学习就是将看得懂的东西使用模型进行压缩,压缩为机器看到懂得东西,进而进行后续操作。
- 后面两个4096的全连接参数量太大了!

- 为了在两个GPU上跑这个模型,Alex用了大量的代码把模型切分为两半边,分别在单个GPU进行训练,搞得这个示意图非常复杂!
- AlexNet用的这个“模型并行”在此之后的很长时间都用的不多!但是(没错,科技是个环,又回来了),随着GPT和BERT的出现,“模型并行”再次被提起!特别是自然语言处理任务中。
🚩Contribution 2: reduce overfitting
- Data Augmentation
- 将256×256的图像随机抠出几个224×224的区域,扩大了数据量
- PCA,主成分分析,在颜色通道上做一些变换
- Dropout
- www.cs.toronto.edu/~nitish/dropout/
- 文章对Dropout的理解和现在大家对其的理解已经不一样了,现在大家认为Dropout是一种正则项
ILSVRC 2013
ZFNet
📄paper: Visualizing and Understanding Convolutional Networks | SpringerLink
💻code:
Matthew D Zeiler, New York University
Rob Fergus, New York University
The approach is based on a combination of large convolutional networks with a range of different architectures. The choice of architectures was assisted by visualization of model features’ using a deconvolutional network, as described in Zeiler et. al “Adaptive Deconvolutional Networks for Mid and High Level Feature Learning”, ICCV 2011.
Each model is trained on a single Nvidia GPU for more than one week. Data is augmented by resizing the images to 256x256 pixels and then selecting random 224x224 pixel crops and horizontal flips from each example. This data augmentation is combined with the Dropout method of Hinton et al. (“Improving neural networks by preventing co-adaptation of feature detectors”), which prevents overfitting in these large networks.
[1311.2901] Visualizing and Understanding Convolutional Networks (arxiv.org)
ZFNet(2013)及可视化的开端 - shine-lee - 博客园 (cnblogs.com)
Clarifai
马修·泽勒(Matthew Zeiler)利用2013年赢得ImageNet挑战赛时的程序创办了Clarifai公司,目前获得了4000万美元风险投资。
机器之心独家对话Clarifai创始人:从图像识别到无限可能-阿里云开发者社区 (aliyun.com)
Clarifai
Matthew Zeiler, Clarifai
A large deep convolutional network is trained on the original data to classify each of the 1,000 classes. The only preprocessing done to the data is subtracting a per-pixel mean. To augment the amount of training data, the image is downsampled to 256 pixels and a random 224 pixel crop is taken out of the image and randomly flipped horizontally to provide more views of each example. Additionally, the dropout technique of Hinton et al. “Improving neural networks by preventing co-adaptation of feature detectors” was utilized to further prevent overfitting.
The architecture contains 65M parameters trained for 10 days on a single Nvidia GPU. By using a novel visualization technique based on the deconvolutional networks of Zeiler et. al, “Adaptive Deconvolutional Networks for Mid and High Level Feature Learning”, it became clearer what makes the model perform, and from this a powerful architecture was chosen. Multiple such models were averaged together to further boost performance.
OverFeat
OverFeat - NYU
Pierre Sermanet, David Eigen, Michael Mathieu, Xiang Zhang, Rob Fergus, Yann LeCun
Our submission is based on an integrated framework for using Convolutional Networks for classification, localization and detection. We use a multiscale and sliding window approach, efficiently implemented within a ConvNet. This not only improves classification performance, but naturally allows the prediction of one or more objects’ bounding boxes within the image. The same basic framework was applied to all three tasks. For the classification task, we vote among different views presented to the network. For localization and detection, each sliding window classification is refined using a regressor trained to predict bounding boxes; we produce final predictions by combining the regressor outputs.
ILSVRC 2014
GoogLeNet (CVPR 2015)✅
📄paper:
- [1409.4842] Going Deeper with Convolutions (arxiv.org)
- CVPR 2015 Open Access Repository (cv-foundation.org)
💻code:
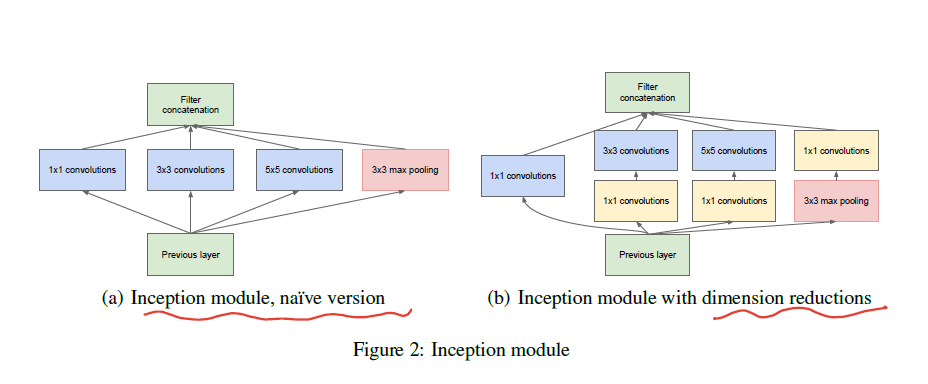
- a deep convolutional neural network architecture codenamed Inception
- the main hallmark of this architecture is the improved utilization of the computing resources inside the network
- increasing the depth and width of the network while keeping the computational budget constant.

VGG (ICLR 2015)✅
📄paper: [1409.1556] Very Deep Convolutional Networks for Large-Scale Image Recognition (arxiv.org)
💻code:
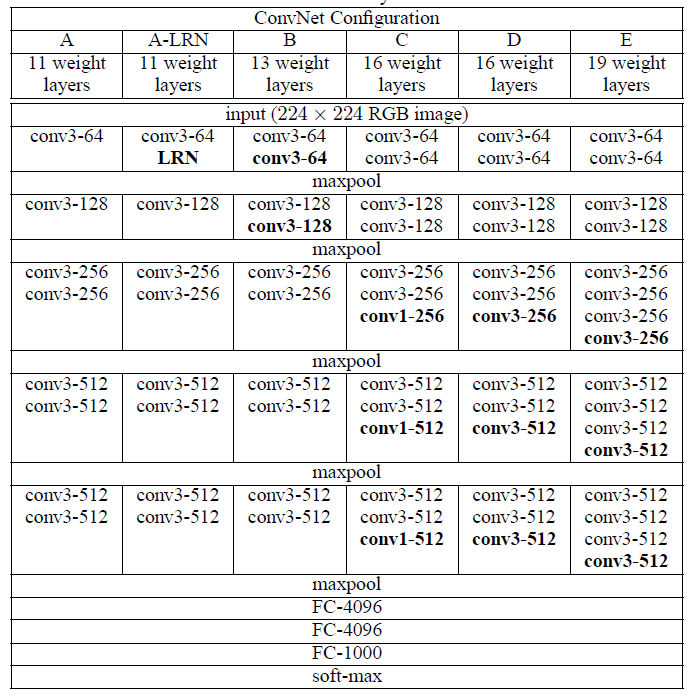
- AlexNet -deeper-> VGG
- AlexNet中出现的卷积核大小为11×11,7×7和5×5,但在VGG中,这么大的卷积核已经见不到了,取而代之的是3×3的卷积核
- VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
ILSVRC 2015
Two main competitions
Object detection for 200 fully labeled categories.
Object localization for 1000 categories.
Two taster competitions
- Object detection from video for 30 fully labeled categories.
- Scene classification for 401 categories. Joint with MIT Places team.
ResNet (CVPR 2016)✅
📄paper:
- [1512.03385] Deep Residual Learning for Image Recognition (arxiv.org)
- CVPR 2016 Open Access Repository (thecvf.com)
💻code:
🔗reference:
🚩intro
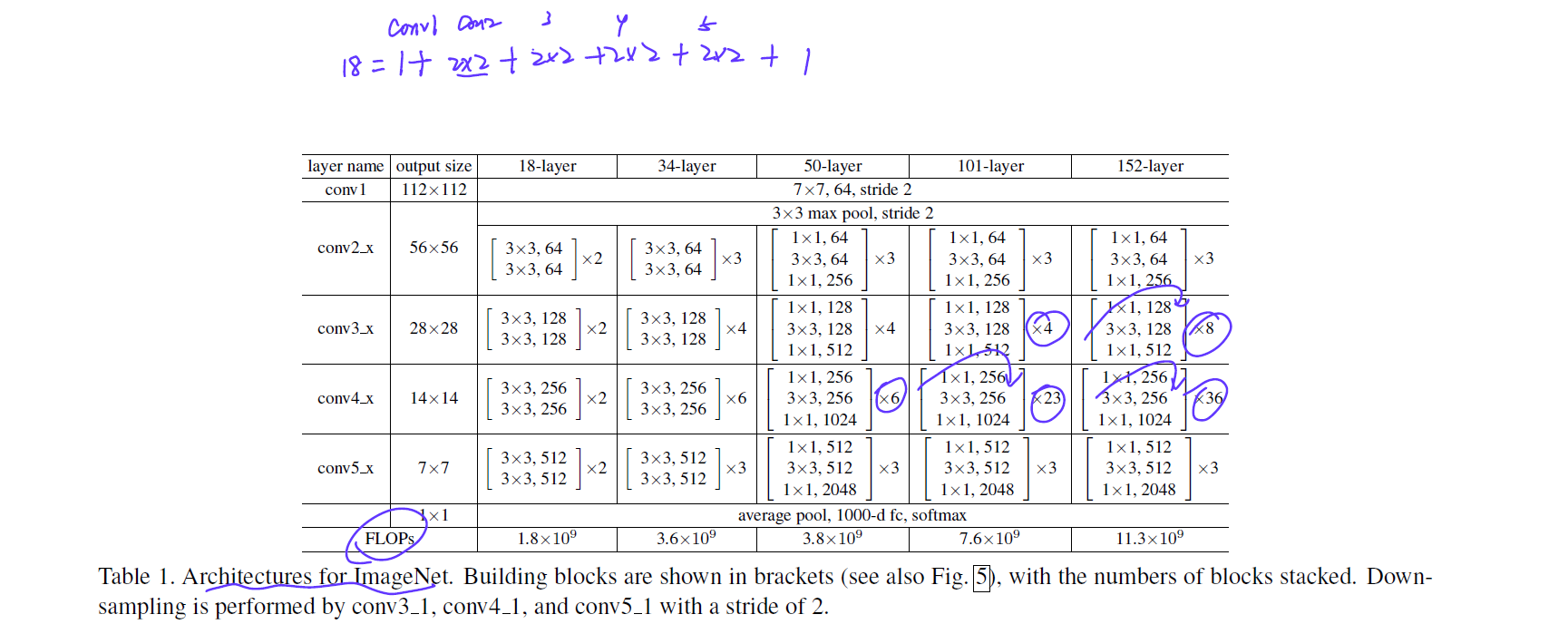
- deeper neural network are more difficult to train!
- residual learning framework: more layers but lower complexity
- residual: $F(x)=H(x)-x$
- 残差连接可以这样理解,如果新加了这些层并不能使模型表现更好的话,就让这个$H(x)->0$.
- 残差连接将模型的复杂度降低了
- shortcut connections(这也是很久之前提出的东西)
- the shortcut connections simply perform identity mapping
- identity shortcut connections add neither extra parameters nor computational complexity
🚩related work
- Resudial Representations
- Shortcut Connections
🚩exp
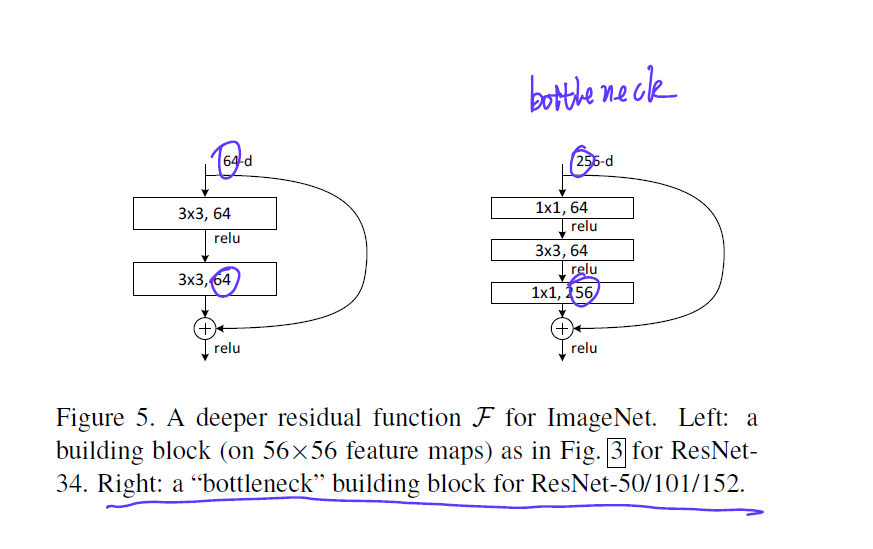
ILSVRC 2016
Trimps-Soushen
📄paper:
💻code:
ResNeXt(CVPR 2017)
📄paper: CVPR 2017 Open Access Repository (thecvf.com)
💻code:
ILSVRC 2017
SENet(CVPR 2018)
📄paper: CVPR 2018 Open Access Repository (thecvf.com)
💻code:
2017-
kaggle
Reference
那些年我们一起追过的ILSVRC冠军_hzhj的博客-CSDN博客
- ImageNet (image-net.org) ↩
- ImageNet (image-net.org) ↩
- supervision.pdf (image-net.org) ↩
- ↩
- weiaicunzai/pytorch-cifar100: Practice on cifar100(ResNet, DenseNet, VGG, GoogleNet, InceptionV3, InceptionV4, Inception-ResNetv2, Xception, Resnet In Resnet, ResNext,ShuffleNet, ShuffleNetv2, MobileNet, MobileNetv2, SqueezeNet, NasNet, Residual Attention Network, SENet, WideResNet) (github.com)[^xx]:ImageNet Winning CNN Architectures (ILSVRC) | Data Science and Machine Learning | Kaggle ↩